Mission-driven Exploration for Accelerated Deep Reinforcement Learning with Temporal Logic Task Specifications



Abstract
This paper addresses the problem of designing control policies for agents with unknown stochastic dynamics and control objectives specified using Linear Temporal Logic (LTL). Recent Deep Reinforcement Learning (DRL) algorithms have aimed to compute policies that maximize the satisfaction probability of LTL formulas, but they often suffer from slow learning performance. To address this, we introduce a novel Deep Q-learning algorithm that significantly improves learning speed. The enhanced sample efficiency stems from a mission-driven exploration strategy that prioritizes exploration towards directions likely to contribute to mission success. Identifying these directions relies on an automaton representation of the LTL task as well as a learned neural network that partially models the agent-environment interaction. We provide comparative experiments demonstrating the efficiency of our algorithm on robot navigation tasks in unseen environments.
Demonstration Videos - TurtleBot 3 Waffle Pi
Simulation Results
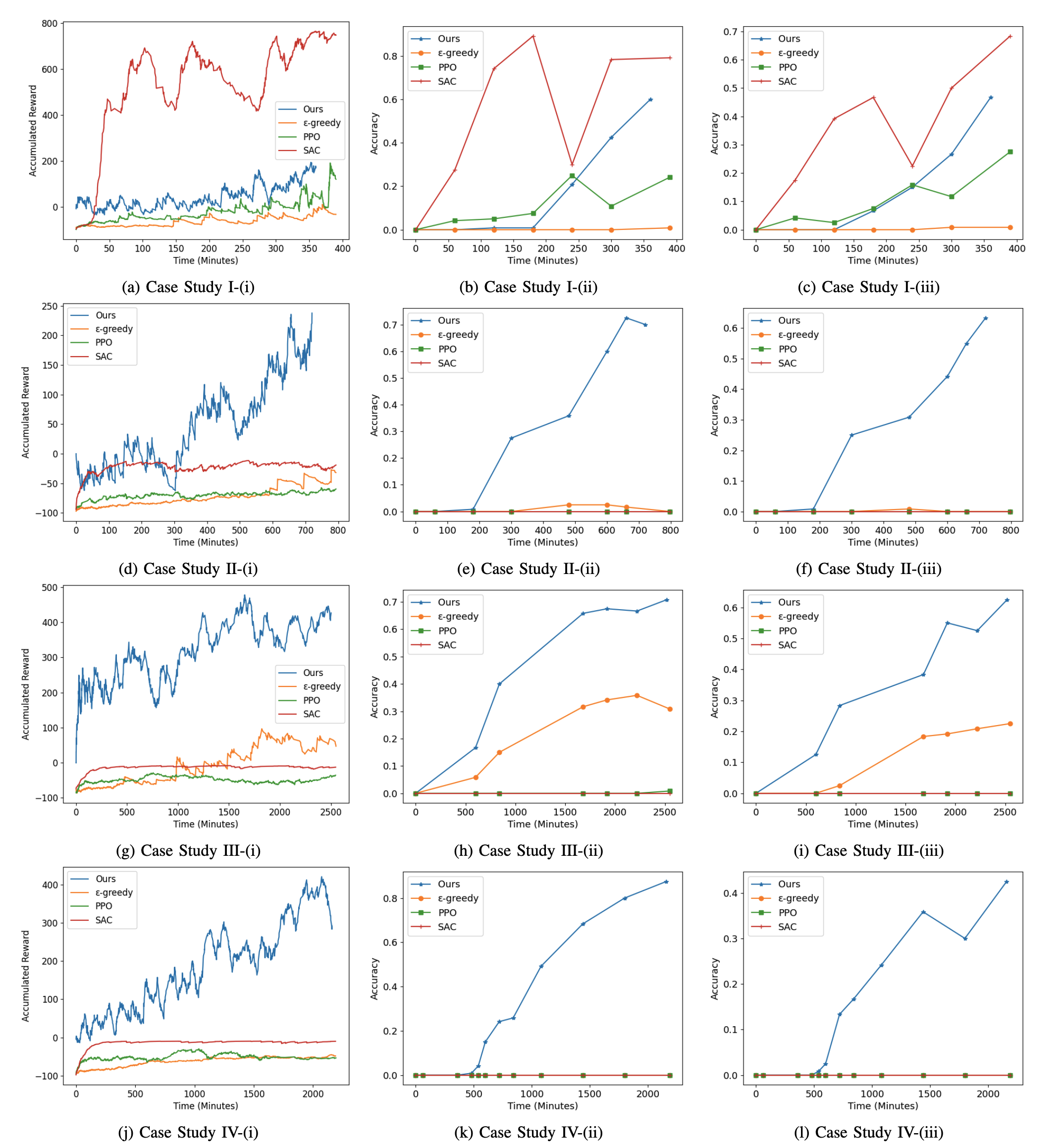
Results of our method, standard DQN, PPO, and SAC.
Citation
Acknowledgements
The website template is from Code as Policies.